
一項關於編碼西夏文的提議——西夏文倉頡輸入法開發報告
The original author is KAWASAKI Keigo (河崎 啓剛).
This is a Chinese translation of his essay.
His original essay in English: A suggestion for encoding Tangut glyphs
本文爲2016年10月8至10日於首爾召開的SCRIPTA會議中河崎啓剛所作發言紀要的中文翻譯。原英文PDF在此:A suggestion for encoding Tangut glyphs
According to the essay, I made a RIME scheme, convenient for inputting: Hulenkius/rime_tangutcjkk
與此文匹配的RIME方案請到此獲取:Hulenkius/rime_tangutcjkk
在開頭必須澄清:本人的西夏文(Tangut)水平尚屬入門級。迄今爲止,本人尚未掌握有關此文字的足够研究知識。儘管如此,本人產生並實現了有關在計算機上輸入西夏文的設想。本人很榮幸能有機會介紹此項研究,並懇請有關方面專家斧正。
此項目是(韓國)國立韓文博物館資助的《韓文與東亞文字的比較》(Comparison of Hangul and East Asian Scripts)項目(負責人:朴振浩 박진호 PARK Jinho)的一部分。該項目涉及八斯巴文、東巴文及西夏文。本人負責西夏文部分的研究。
2024/6/9 更新:
新製西夏倉頡在線練習工具,請訪問:https://vistudium.top/tangut/
一、引言
2016年1月,6125個西夏文字(Tangut)及755個西夏文構件(Tangut components)被收錄進入統一碼9.0(Unicode 9.0),這爲計算機協助研究西夏文提供了可能。論及此種文字目前的標準輸入方式,由李範文(1997)根據「四角號碼」所創製的输入法可谓無出其右。但此種方式卻不堪稱作最佳選擇,因爲它存在以重碼爲例的許多問題。因此,本人嘗試開發一種較理想的輸入法,以便利西夏文的計算機處理。我將倉頡輸入法——這一有代表性的形碼輸入法——改製爲西夏文倉頡輸入法。
倉頡輸入法,作爲形碼輸入法的鼻祖,由臺灣人朱邦復於上世紀70年代開發,並尚在港、臺等繁體中文界使用。使用倉頡輸入法,在不知字音的情況下仍能憑藉字形高效輸入漢字,因此,倉頡輸入法是本人在日常學術工作中的首要選擇。
統一碼9.0目前已囊括約80,000個漢字(包括繁體中文、簡體中文、日文及其他),而倉頡輸入法能够支持這整個字符集。倉頡輸入法對於處理包含罕用字的歷史文獻,以及區分異體字都具有很大幫助。
重碼,是包括音碼在內的中文輸入法最爲棘手的問題,而倉頡輸入法以最低的重碼實現了輸入過程的極高效率。
倉頡輸入法及其改版在輸入比賽中常拔得頭籌。熟練的輸入員可在一分鐘之內輸入200個字。
當使用倉頡輸入法輸入漢字時,須將漢字拆解成總數約爲100的基本構件(即「字根」),並將其分配至A到Z鍵的其中一個上。據稱,對初學者來說,記憶這些字根的負擔是該輸入法的最大缺點。所幸,西夏文是在較短一段時期內人爲發明的,因此有較強的透明度與可分析性。某種意義上,西夏文可以看作人造的僞漢字。因此記憶字根的負擔並不太重。簡言之,將原版倉頡輸入法改製以適應西夏文,將可能製成一種比原版更易學的、接近理想的輸入法。
在此,本人將介紹西夏文倉頡輸入法的優點與適用性,並將討論此輸入法採用現有形式的原因。
二、西夏文倉頡輸入法
首先,本人將簡述西夏文倉頡輸入法的具體形式。
圖1顯示了輸入的過程;圖2是鍵位佈局;表1是部分輸入碼舉例。
藉助輸入法編輯器(IME, Input Method Editor),倉頡輸入法可以輸入任何爲之定製的內容。自然,若要使倉頡輸入法支持西夏文,IME就必須能够處理包括西夏文在內的額外平面。在圖1中,每個候選字後都有許多信息,這是我從「古今文字集成」網站(http://www.ccamc.co/)上獲取的。數據如下:西夏文字符、西夏文倉頡輸入碼、四角號碼、龔煌城擬音、Marc Miyake擬音、《簡明夏漢字典》釋義、英文釋義、《同義》釋義。
 」(十)。)
」(十)。)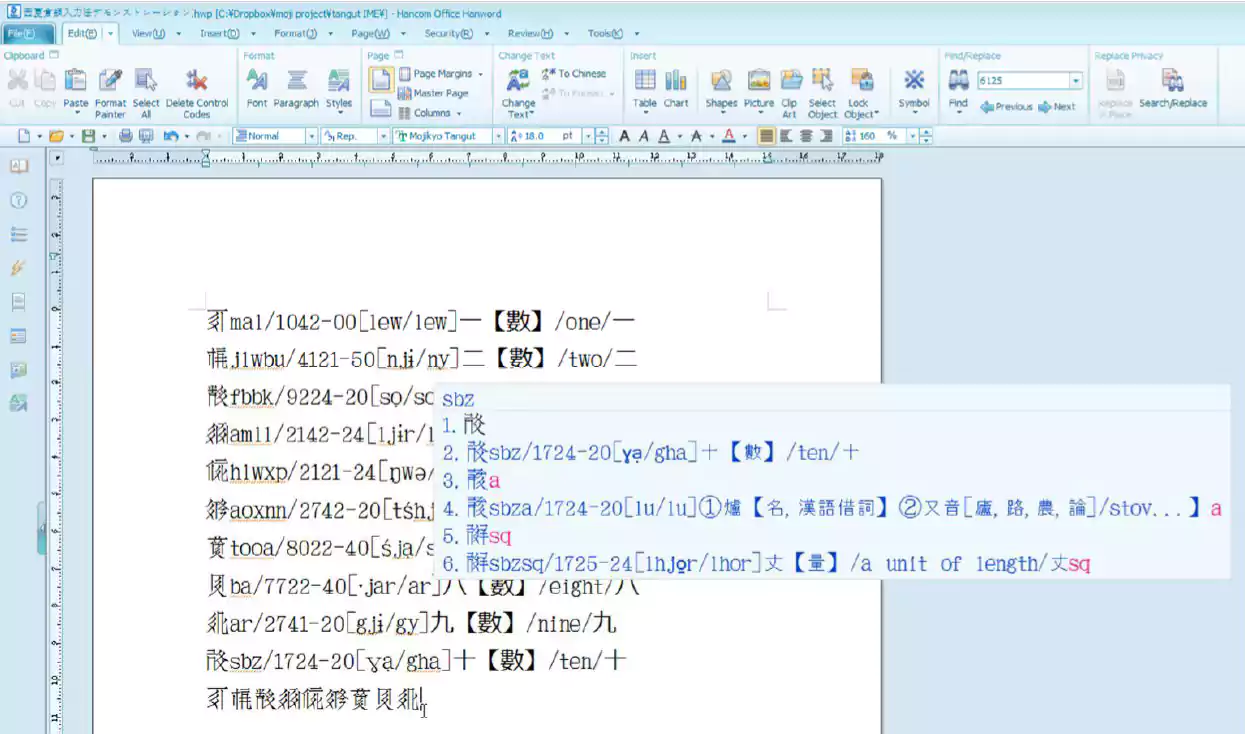

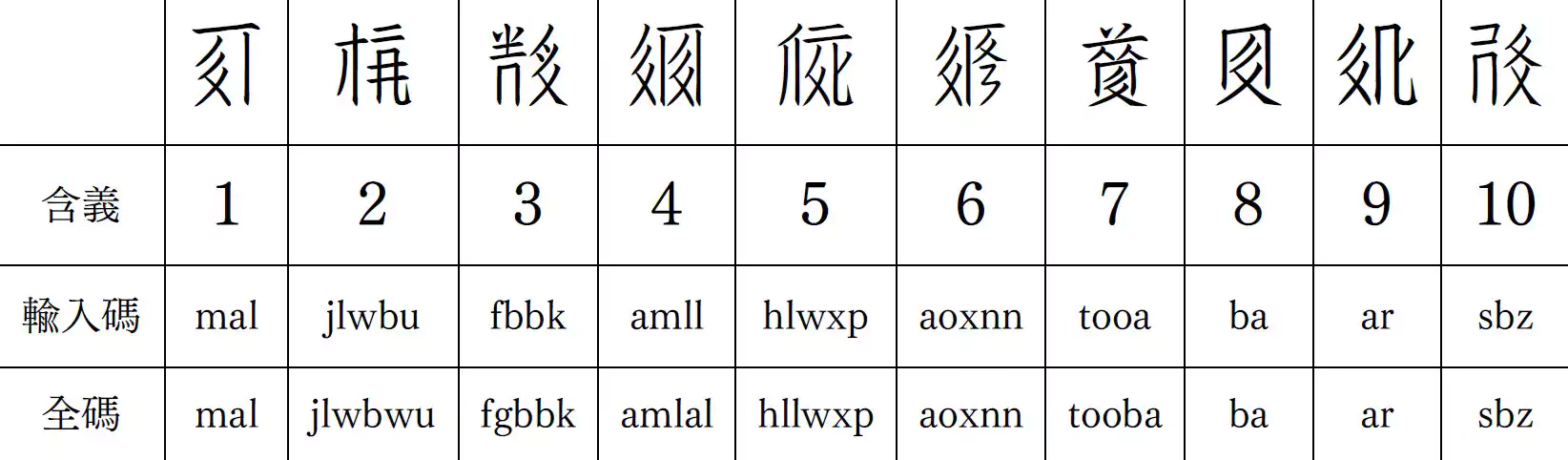
西夏文倉頡輸入法首先將目標字符拆成部件(即字根),再用羅馬字母進行編碼,這一過程的結果爲「全碼」。在全碼的基礎上,再規則化爲至多5各字母,形成「輸入碼」,其規則如下:
①整體字
→[首碼,次碼,三碼……尾碼](至多四碼)
②組合字
→[首碼……尾碼],[首碼,次碼……尾碼]
(字首至多兩碼,字身至多三碼)
→[首碼……尾碼],[[首碼……尾碼],[……尾碼]]
(若字身還能分割,則按相同方式再分割爲次字首、次字身)
舉例:

在西夏文的情況下,幾乎沒有超過4個字根的整體字,所以規則②就是自然而然的了。
爲何選擇倉頡?
目前已經有幾項編碼西夏文以適用輸入法的嘗試。例如由李範文編制的四角號碼(1997, 2008, 2012)以及由統一碼聯盟(Unicode Consortium)提出的N4522筆序碼。

U+185CF [dzwə/dzwy] 鑷子【名】/tweezers/镊子
N4522筆序碼:DCGABBBDCGCCQACCQCCCQ(21畫)
四角號碼:8044-40
西夏文倉頡碼:RJRXA(←[R TJ][[RX][MX A]])
然而,四角號碼有嚴重的重碼問題,例如,單是「8044-40」一個碼就對應了九個字:








而在N4522筆序碼中,碼長厚積。出於這些原因,這兩種輸入法的效率都不高。
如果是這樣,或可認爲N4522筆序可以通過規則化縮碼、模仿倉頡輸入法從全碼中擷取部分碼等方式加以改進,但這會造成重碼問題。爲此需要以倉頡輸入法字根的尺度對字根進行分析。詳情請參見第五節。
重碼的問題,是指不同字對應的輸入碼雷同。在四角號碼輸入法中,最高頻率重碼對應34個字。而其平均重碼率爲74%,意味着在四分之三的情況下,屏幕上會出現不止一個的候選字,用戶不得不在其中進行選擇,這些候選字或能多達數十字。另一方面,在西夏文倉頡輸入法中,最高頻率重碼僅對應5個字,而平均重碼率爲14%。在這些輸入法的實際使用中,效率的差距是不言自明的。
可簡明計算如下:四角號碼碼長爲6,理論上可以區分10⁶ = 1,000,000種情況;相比之下倉頡輸入法碼長至多爲5,理論上可以區分26 + 26² + 26³ + 26⁴ + 26⁵ = 12,356,630種情況。後者比前者勝出一個數量級。
下方爲兩者最高頻率重碼舉例:

除了倉頡輸入法外,其他的形碼輸入法還包括:鄭碼輸入法、五筆字型輸入法、大易輸入法、嘸蝦米輸入法、行列輸入法等等。倉頡輸入法以其普及度、易學性、重碼率,尤其是其「小字根」原則6等因素,成爲本人的決定基礎。
例如,在倉頡輸入法中,「言」字拆爲:亠 (y) + 一 (m) + 一 (m) + 口 (r),而「車」字拆爲:十(j) + 田(w) + 十(j)。諸如亠 (y)、一 (m)、十(j)之類的字根在西夏文中同樣適用。但如果以類似漢字「言」「車」之類的較大單位作爲字根,在編碼西夏文時就毫無用處了。因此,字根不宜太大。
倉頡輸入法有最小、最少的字根。朱邦復(1995)指出,在倉頡五代輸入法中,有114個字根(包括倉頡字母與輔助字形)。西夏文倉頡輸入法的字根數要少得多,約有70個,其中有40個與原版倉頡輸入法互通。
衆所周知,西夏文源出漢字,因此使現存的漢字輸入法應用至西夏文就再好不過了。試設想將西夏文與漢字之間最相似的部件作爲字根,那就更爲理想了。從這一點上看,倉頡輸入法已經接近理想。倉頡輸入法有着大小合適的字根,能够處理多達80,000個的漢字——不論是繁體字、簡化字還是和製漢字,因此也能處理任何有着與漢字相似外觀的文字,包括西夏文。
最後我想指出,西夏文倉頡輸入法比原版倉頡輸入法要容易得多。可以大言不慚地說,西夏文比漢字更加適合倉頡輸入法。西夏文是短時間內人工創制的;不像中文,西夏文還幾乎全都運用了部件拼字法,所以將其拆解爲部件極其簡單。原版倉頡輸入法據說有一個缺點,即其拆字規則的背誦負擔,但適用到西夏文之後,僅有的這一缺點也會消除。
西夏文倉頡輸入法的特點及優點可歸納爲如下幾點:
①僅用至多5個羅馬字母(a-z)就能輸入全部6,125個西夏文字符。
②重碼率僅爲14%,意味着86%的西夏文字符可以無選上屏。
③字根數量僅爲70左右,其中有40個與原版倉頡輸入法共通。
④西夏文的高度分析性使西夏文倉頡輸入法比原版倉頡輸入法更容易學習。
三、西夏文倉頡輸入法的進階應用
在第二節中,本人從輸入法本身的角度介紹了西夏文倉頡輸入法。這固然是此工作的出發點,但本研究具有更多適用性上的價值。
上文已提到,朱邦復(1999: 4-11)爲倉頡輸入法發明者。他稱此輸入法只是其宏大計劃的第一階段或底層應用。
直接、機械地從西夏文字形生成輸入法與全碼,這意味着什麼?除了作爲一種輸入法外,它還有兩種重要用途:
⑤西夏文倉頡輸入法的全碼是字形分析的利器。彈指之間,便可利用全碼檢索含有某部件的字符,進而高效研究部件分佈、含義與語音特徵。
⑥全碼使依照語義部首進行自動排序字符成爲可能,可以作爲字典序使用。其重碼率(3.7%)遠低於輸入碼的重碼率,且最高頻率重碼字數爲3,與四角號碼相比有着顯著優勢。李範文(1997, 2008, 2012)採用四角號碼作爲排序依據,由於四角號碼本身的無義性,重碼率高出許多(74%),最高頻率重碼字數爲34。
誠然,在採用倉頡碼作爲字典序之前,必須完善西夏文倉頡輸入法並標準化其編碼。這可能需要耗時研討,但一旦標準化完成,就能因其基於字形的排序而有各方面應用。
下文將具體解釋觀點⑤,即西夏文倉頡輸入法的全碼是字形分析的利器。例如,當需檢索所有包含西夏文部件「 」(全碼ho, U+18841)的字時,僅需搜索「ho」,就能在一秒之內從6,125個西夏文字符中檢出54個匹配字:(譯者案:實爲53字,原文重複
」(全碼ho, U+18841)的字時,僅需搜索「ho」,就能在一秒之內從6,125個西夏文字符中檢出54個匹配字:(譯者案:實爲53字,原文重複 字)
字)




















































從這些字符中可以歸納出一種共同特徵:「」常與在右的「 」共同組成「
」共同組成「 」(hol, U+18889)。假定三個層次「字形-部首-筆畫」與口語中的「詞語-語素-音素」三個層次平行,則「」對應一個「部首」,是最小有義單位,而「」只是一個無義的筆畫集合。
」(hol, U+18889)。假定三個層次「字形-部首-筆畫」與口語中的「詞語-語素-音素」三個層次平行,則「」對應一個「部首」,是最小有義單位,而「」只是一個無義的筆畫集合。
類似地,「 」(bd, U+1883F)與「
」(bd, U+1883F)與「 」(bl, U+1883B)之間的差異同樣有趣:它們是否真的有差異?因此,通過檢索含有這些部件的字符,得出結果:前者僅出現在「
」(bl, U+1883B)之間的差異同樣有趣:它們是否真的有差異?因此,通過檢索含有這些部件的字符,得出結果:前者僅出現在「 」(mbd, U+1886E)中,而後者僅出現在「
」(mbd, U+1886E)中,而後者僅出現在「 」(sbl, U+18939)和「
」(sbl, U+18939)和「 」(ssbl, U+18A30)中。亦即,這三者爲真正的部首,而「」和「」僅爲筆畫集合。
」(ssbl, U+18A30)中。亦即,這三者爲真正的部首,而「」和「」僅爲筆畫集合。
除此之外,罕用部件「 」(il?)、「
」(il?)、「 」(ml?, U+1880c)以及「
」(ml?, U+1880c)以及「 」(md?, U+1880F)在現有的各個字體中有不同形式,缺乏一致性。通過檢索包含僅基於字形確定的「il」「ml」及「md」三個碼,可以發現,上述三個部件僅出現在部首「
」(md?, U+1880F)在現有的各個字體中有不同形式,缺乏一致性。通過檢索包含僅基於字形確定的「il」「ml」及「md」三個碼,可以發現,上述三個部件僅出現在部首「 」(a, U+1888C)右方。在此基礎上得出結論:這三者很可能只是「
」(a, U+1888C)右方。在此基礎上得出結論:這三者很可能只是「 」(ao)的手寫變形。在當前版本的輸入方案中,這三者都以標準碼「ao」輸入,解決了輸入的不便。下方給出了32個含有「ao」碼的字,偏上一行是用景永時字體顯示的字符,而偏下一行爲今昔文字鏡(Konjaku Mojikyo)字體的顯示,注意其中的不統一性:
」(ao)的手寫變形。在當前版本的輸入方案中,這三者都以標準碼「ao」輸入,解決了輸入的不便。下方給出了32個含有「ao」碼的字,偏上一行是用景永時字體顯示的字符,而偏下一行爲今昔文字鏡(Konjaku Mojikyo)字體的顯示,注意其中的不統一性:

上述結論僅在分析兩種字體的基礎上得出,缺乏詞義或實際語言資料的支撐,因此尚非定論。抛開這種試探性,更爲重要的是採用西夏文倉頡輸入法全碼進行字形分析的高效性。
這種檢索含有特定部件字符的能力除了組織字形外,還能進一步分析部件的分佈、含義與語音特徵。
四、設計理念以及與原版倉頡的差異
本人在設計西夏文倉頡輸入法時,慮及西夏文的特點,對原版倉頡輸入法作出了一定更改。下文將闡釋作出這些修改的理念依據及此輸入法採用現有形式的原因。
如上所述,倉頡輸入法自身在學術上很受歡迎,所以西夏文倉頡輸入法最好能基本沿用目前的倉頡輸入法。因此,本人在原則上儘可能沿用原版倉頡的字根與鍵位,並在有必要作出改動時儘量減輕使用者的額外記憶負擔。
下文將指出對原版倉頡作出的更改。下面是與原版倉頡的字根和鍵位佈局的比較,西夏文倉頡輸入法尚在開發階段。

圖4:西夏文倉頡輸入法鍵位佈局(第三版)
首先,原版倉頡輸入法分配給「A」(日)、「R」(口)和「W」(田)的字根在西夏文中完全未使用。「Z」鍵在原版倉頡中本身就沒有使用。「X」(難)則僅爲拆分難字的鍵,西夏文由於拆分簡易,並不需要這個特殊的鍵。因此如果完全沿用原版倉頡輸入法,那麼「A」「R」「W」「Z」和「X」五個鍵位就浪費了。
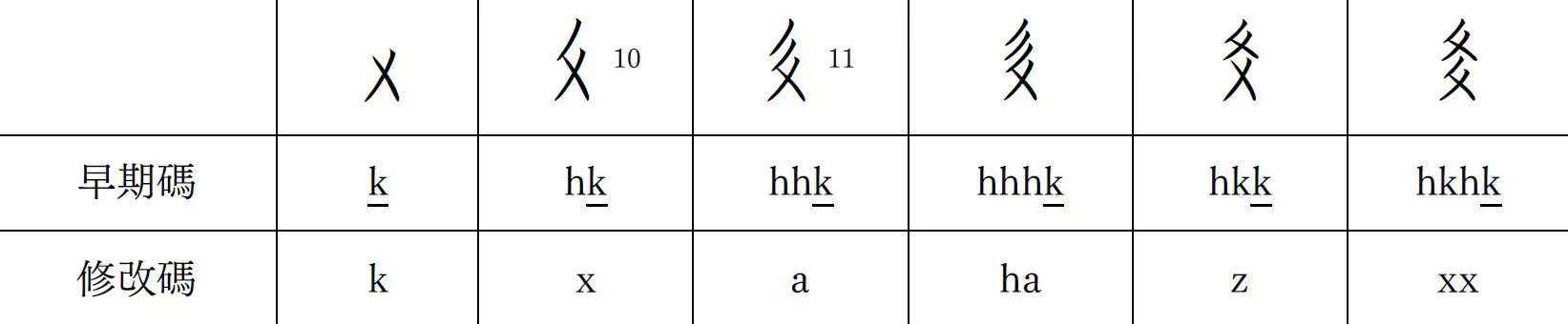
本人在此項目的早期開發階段發現,如果依照原版倉頡,那麼會造成大量以「 」(k)和「
」(k)和「 」(p)的字符出現重碼,這將削弱倉頡輸入法的低重碼優點。
」(p)的字符出現重碼,這將削弱倉頡輸入法的低重碼優點。
爲了充分發揮倉頡的長處,需要通過在最小尺度上區分尾碼來進行降重。爲此,本人擷取了相對大於「」(k)和「」(p)的常用部件,並將之定爲額外字根,分配至尚未使用的「A」「R」「W」「Z」和「X」鍵上。
以「」(k)結尾的字符配置如下(「X」「A」以及「Z」都位於鍵盤的左下部):
以「」(p)結尾的字符配置如下(「P」「O」「Y」「R」「E」以及「W」都位於鍵盤的第二行):
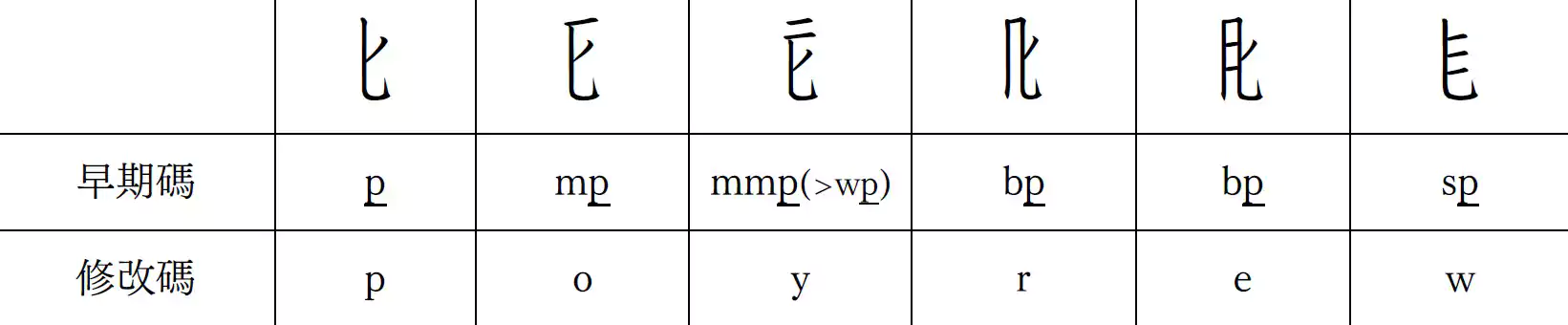
在進行了上述區分後,最高頻尾碼成爲了「x」(848)、「a」(665)和「p」(655),並仍然不會使最高頻重碼字增多。事實證明,這樣的劃分是很有效的。(試想「x」和「a」兩者竟一度混合成「k」!)
在設計區分方式時,鍵位佈局同樣需要考慮在內,以減輕用戶的記憶負擔。「O」「Y」「E」等鍵比較罕用,所以本人將其分配給各個額外字根,不會造成太大問題。
區分「」(k)和「」(p)是西夏文倉頡輸入法的首要改動。此後還加入了新的字根來緩和重碼,並更好體現西夏文特徵。這個過程遵循了以下原則:
①同一個鍵上的字根須儘可能有關聯、便於聯想記憶。
②新出現的重碼須在統計上越少越好。
因此本人推導出一些西夏文倉頡輸入法的特有字根,並實現了14%的平均重碼率和5個字的最高頻率重碼字。
誠然,輸入法的目前形式尚不完善,本人將通過不斷測試追求更爲理想的形式。
五、結論
在本文中,我介紹了西夏文倉頡輸入法及以之進行西夏文編碼的意義。這稱得上是一套較爲理想的系統,是一種易學、高效的輸入法。全碼,作爲開發過程中的副產品,是分析字形的利器,可用於研究部件的分佈、含義和語音特徵。它還可以作爲字典序使用:這種排序的意義在於可以依照部首自動排序。
高效的輸入法可以幫助學習者有效地查閱字典,這與高效學習西夏文直接相關。此外,它還能使我們有效地建立大規模的西夏文-中文平行語料庫。該研究預計將便利西夏文的學習與處理,並有利於今後西夏語言文字的研究。
參考資料
[1] 景永時,賈常業. 《西夏文字處理系統》[M]. 銀川:寧夏人民出版社. 2007.
[2] 李範文. 《夏漢字典》[M]. 北京:中國社會科學出版社. 1997.
[3] 李範文. 《夏漢字典》(修訂版)[M]. 北京:中國社會科學出版社. 2008.
[4] 李範文. 《簡明夏漢字典》[M]. 北京:中國社會科學出版社. 2012.
[5] Unicode Consortium. Proposal to encode the Tangut script in the UCS[EB/OL]. 2014. http://std.dkuug.dk/jtc1/sc2/wg2/.
[6] Jerry. 古今文字集成[CP/OL]. http://www.ccamc.co/.
[7] 朱邦復. 《第五代倉頡輸入法手冊》[M]. 香港:文化傳信有限公司. 1999.
一項關於編碼西夏文的提議——西夏文倉頡輸入法開發報告